Coarse-to-Fine
Formal definition
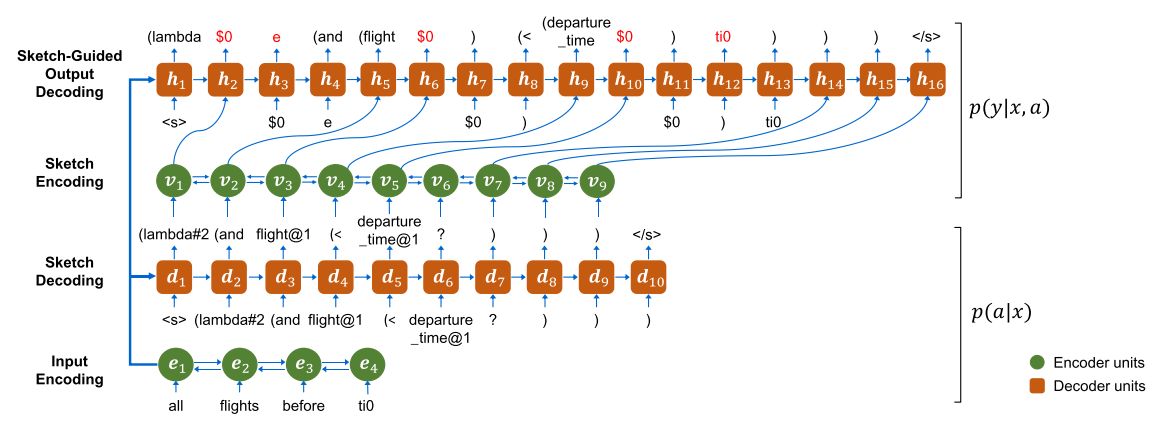
The input of the model consists of a sequence where each is natural language utterance, such as . The final output (i.e. code tokens) is represented as a sequence . The goal is to estimate the probability of generating the sequence , given the input , i.e. , while considering the sketch . Therefore, the probability is factorized as
where
We see that the generation of the next token fully depends on the previously generated tokens of the same kind. For the final output, the entire sketch is also considered. This factorization clearly emphasizes the two-step process.
The , modeled as a bi-directional recurrent neural network with LSTM units, produces vector representations of the natural language input , by applying a linear transformation corresponding to an embedding matrix over the one-hot representation of the token: Specifically, each word is mapped to its corresponding embedding (e.g. GloVe word embeddings). The output of the encoder is , which denotes the concatenation of the forward and backward passes in the LSTM function. The motivation behind a bi-directional RNN is to be able to construct a richer hidden representation of a word vector, making use of both the forward and backward contexts.
The is also a RNN with LSTM cells. Furthermore, an attention mechanism for learning soft alignments is used. An attention score , which the contribution of each hidden state, is computed, corresponding to the -th timestep, on the -th encoder hidden state, where is the hidden state of the decoder. Thus, at each timestep we get a probability distribution over the hidden states of the encoder:
with
Now we can compute the probability of generating a sketch token for the current timestep:
where
is the expected value of the hidden state vector for timestep , and
is the output of the attention. are learnable parameters, and is the hidden state of the decoder. Therefore, Dong and Lapata define the probability distribution over the next token as a linear mapping of the attention over the hidden states of the input encoder.
Regarding the , a bi-directional LSTM encoder constructs a concatenation , similar to the input encoder.
The is also a RNN with an attention mechanism. The hidden state is computed with respect to the previous state , and a vector . If there is a one-to-one alignment between the sketch token and the output token , then , the vector representation of , otherwise .
The probability distribution is computed in a similar fashion to , namely as a softmax over the linear mapping of the attention over the hidden states of the sketch encoder.
The goal here is to constrain the decoding output by making use of the sketch. For instance, we know that some number must be generated as part of if the corresponding sketch token is . Moreover, there may be situations where the output token is already generated as part of the sketch (e.g. a Python reserved name, such as ), in which case must directly follow the sketch.
An important thing to mention is the , which decides if a token should be directly copied from the input (e.g. in case of out-of-vocabulary words, such as variable names), or generated from the pre-defined vocabulary. To this extent, a copying gate is learned:
where is hidden state of the sketch decoder. The distribution over the next token becomes:
where is the attention score which measures the likelihood of copying from the input utterance , and is the vocabulary of output tokens. Therefore, selects between the original distribution , in which case no copy is being made, and the weighted sum of the attention scores for the out-of-vocabulary tokens.
Finally, we discuss model’s training and inference. Since the probability of generating a specific output, given the natural language input is factorized as:
taking the log of both sides gives the log-likelihood:
so the training objective is to maximize this log-likelihood given the training pairs in the dataset (where denotes the model’s parameters):
Naturally, at test time, the sketch and the output can be greedily computed as such: